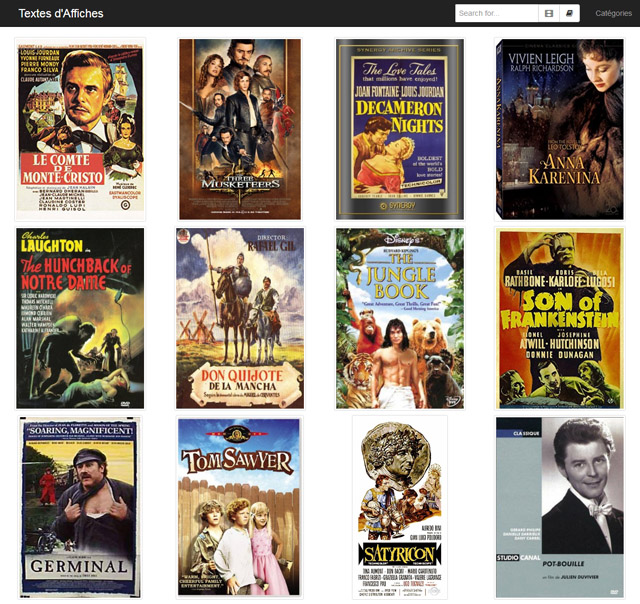
Un week-end de novembre en 2016 se déroulait un hackathon à la BnF. Notre groupe, composé d’Aliénor, Anna, Benoît, Karl, Liberté, Moustafa et Nicolas, s’était consacré à un projet sur les adaptations littéraires en films. La procrastination étant, il aura fallu 6 mois pour finaliser le projet, sorti en mai 2017, et 5 mois de plus pour écrire ce billet.
Le pitch : Textes d’Affiches est une interface qui met en relation directe les films avec les œuvres littéraires adaptées, accessibles sur Gallica. Inversement à partir de livres accessibles sur Gallica on peut en retrouver les adaptations cinématographiques.
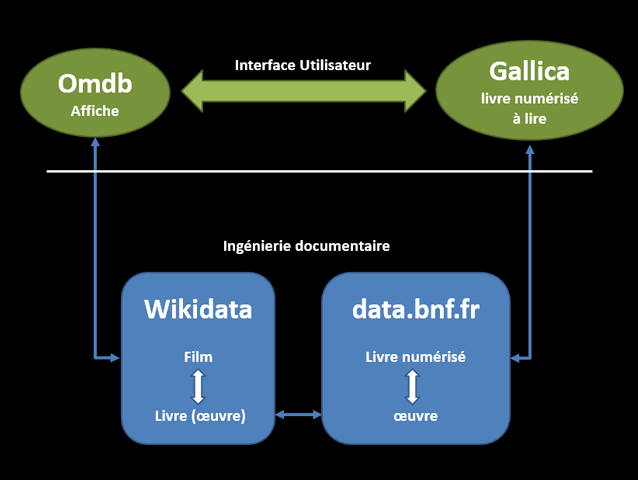
Les affiches sont récupérées de la base OMDb, les données de mise en relation de Wikidata et data.bnf.fr.
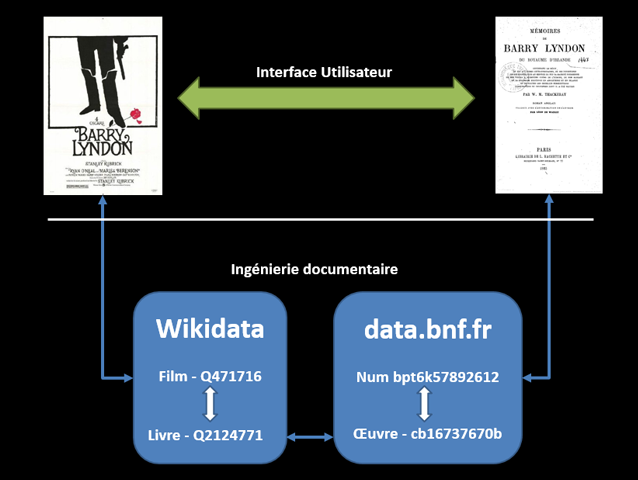
Par exemple, Textes d’Affiches met en relation Barry Lyndon, le film de Stanley Kubrick, avec le roman de William Makepeace Thackeray Mémoires de Barry Lyndon lisible sur Gallica :

Dans l’autre sens, on peut vouloir retrouver les adaptations de L’Île mystérieuse de Jules Verne :

La fabrique documentaire
L’essentiel en un schéma :
Exemple avec Barry Lyndon :
La récolte des donnée va s’appuyer sur 2 requêtes SparQL : l’une sur l’Endpoint de Wikidata, l’autre sur celui de data.bnf.fr.
Dans Wikidata, il y a des éléments ayant en nature film. Les films peuvent avoir la propriété basé sur/P144 renseignée les liant à d’autres éléments de Wikidata. Ces autres éléments liés peuvent être des livres ou des œuvres littéraires, et celles-ci peuvent avoir la propriété identifiant BnFbasé sur/P268 renseigné. Du coup, on peut faire une relation entre un élément film et l’identifiant BnF de l’œuvre adaptée.
Et hop, une requête SparQL pour récupérer le tout :
SELECT DISTINCT ?film ?IMDb (GROUP_CONCAT(DISTINCT ?IDBnF; separator=";") as ?IDsBnF)
WHERE {
?film wdt:P31/wdt:P279* wd:Q11424.
# on recherche des éléments ayant nature film/Q11424 ou une sous-classe
?film wdt:P144 ?oeuvre.
# "basé sur"/p144 une oeuvre, propriété
{?oeuvre wdt:P31/wdt:P279* wd:Q571} UNION {?oeuvre wdt:P31/wdt:P279* wd:Q7725634}
# l'oeuvre a en nature livre/Q571 ou oeuvre littéraire/Q7725634 (ou sous-classe)
?oeuvre wdt:P268 ?IDBnF. # l'oeuvre a un idenfiant BnF/propriété P268
?film wdt:P345 ?IMDb # le film a un identfiant IMDb
}GROUP BY ?film ?IMDb
Cette requête fournit une liste de résultats avec 3 données :
- l’identifiant Wikidata d’un film . Exemple : Q471716
- l’identifiant IMDb de ce film. Exemple : tt0072684
- l’identifiant BnF du livre (ou œuvre littéraire) adapté. Exemple : cb16737670b
[NB : du point de vue FRBR, on cherche des œuvres dans le catalogue de la BnF]
Sur les éléments films sur Wikidata, la propriété IMDb (Internet movie database) peut être renseignée. Cet identifiant fait autorité dans les bases de films et nous permet via l’API OMDb (Open movie database) de récupérer des images d’affiches.
Maintenant qu’on a des films avec affiches et adaptations littéraires identifiés sur Wikidata, on va chercher via data.bnf.fr les livres correspondants en accès sur Gallica.
Et hop, une deuxième requête SparQL :
SELECT DISTINCT ?gallica WHERE {
?manif rdarelationships:workManifested
<http://data.bnf.fr/ark:/12148/cb16737670b#frbr:Work>;
# cb16737670b est l'identifant changé à chaque requête
rdarelationships:electronicReproduction ?gallica
}LIMIT 1
requête SparQL sur data.bnf.fr
Cette requête fournit à partir d’un identifiant œuvre (FRBR) une manifestation (FRBR) numérisée. La requête est exécutée pour chaque œuvre récupérée comme adaptation littéraire depuis Wikidata. S’il n’y a pas de numérisation accessible, le film est mis de côté et ne sera pas restitué.
On remarque ici tout l’intérêt du chantier de FRBRisation du catalogue actuellement en cours à la BnF, réalisé dans le cadre de la transition bibliographique. Ce sont bien les concepts d’œuvre et de manifestation au sens FRBR et leur articulation qui sont les rouages essentiels permettant ce liage sémantique entre films et livres à lire.
Les requêtes fédérées
Pour trouver les unités documentaires du projet, on a utilisé 2 requêtes SparQL. Dans la philosophie du web sémantique, une seule aurait pu suffire. Et justement l’Endpoint de Wikidata permet les requêtes fédérées. Malheureusement l’Endpoint de data.bnf.fr ne permet pas encore ce type de requêtes tierces. Souhaitons que cela soit prochainement possible. Non seulement parce que cela correspond à l’idée et aux attentes du web sémantique, mais surtout car cela serait une belle opportunité, pour faciliter certaines choses auxquelles nous avons pensé et également pour celles que d’autres créeront et auxquelles nous n’aurions sans doute jamais pensé, et qui en seront d’autant favorisées.
Maintenant qu’on a les identifiants de toutes les unités documentaires désirées, on récupère toutes les informations de notice sur Wikidata par négociation de contenu et on compile le tout.
Le service web se décompose en 2 parties :
- Une API, yolo
- Une interface utilisateur
La documentation de l’API présente les différentes possibilités de requête. Elle est disponible avec le code source sur Github : https://github.com/zone47/tda.Il est par exemple possible avec l’API de récupérer les adaptions d’Othello de Shakespeare : http://zone47.com/tda/api/?type=books&q=Q26833.
L’interface web a été développée par Karl Pineau et le code source est aussi sur Github : https://github.com/KarlPineau/TextesdAffiches/
Bilan

Un grand merci aux équipes de la BnF pour un accueil et une orga au top, #HackathonBnF
Tout d’abord, le projet n’a été possible que grâce à l’œuvre de Coyau côté Wikidata. Il a amorcé la pompe documentaire, puis renseigné énormément de déclarations basé sur/P144 pour les adaptations cinématographiques et nous a fait découvrir, entre autres, tout plein d’adaptations des Trois mousquetaires. Il a également renseigné sur de très nombreux éléments films de Wikidata des versions visibles en ligne sur Internet Archive, WikiCommons ou Youtube. Pour une vingtaine de films dans Textes d’Affiches, on peut ainsi accéder à leur visionnage en ligne, comme par exemple pour L’Étroit Mousquetaire (1922) de Max Linder accessible sur Commons.
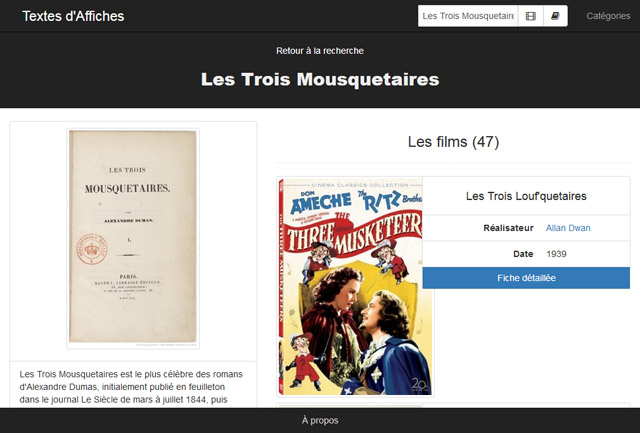
Les Trois Mousquetaires à lire sur Gallica, avec ses adaptations – Merci Coyau :’-)
Avant de se lancer, un petit sondage préalable dans les données et leur liage avait révélé qu’il y avait a priori matière à faire quelque chose. Les aléas du hackathon étant, le projet n’avait pu aboutir dans le temps du week-end. Heureusement il a été repris ensuite et une version fonctionnelle a pu être publiée.
Si la mise en relation fonctionne plutôt bien, plusieurs achoppements sont apparus :
- parfois le document littéraire est en fait un fichier audio,
- le lien n’est pas toujours direct dans les cas de recueil,
- l’ontologie déduite des sous-classes de l’élément film/Q11424 sur Wikidata dérive un peu par rapport à l’attendu (même si, ma foi, l’effet de bord est plutôt appréciable),
- toutes les images ne sont pas des affiches,
- ces affiches ne sont pas souvent en français,
- plus globalement le projet ne gère pas le multilinguisme.
Bref il aurait fallu plus travailler au traitement et à la réédition des données (comme d’habitude) et sans doute que l’interface pourrait être améliorée.
Malgré cela, les processus automatiques ont bien fonctionné, les notices sont bien remplies, Wikidata et data.bnf.fr ont chacune parfaitement joué leur rôle, on a pu faire ressortir des livres sur Gallica et en trouver des adaptions cinématographiques ; l’essentiel voulu y est et ça marche.
L’idée de départ pour Textes d’Affiches était de créer une interface mettant en relation directe deux objets familiers, l’affiche de film et le livre. Il y avait une volonté de squeezer au maximum les « interfaces documentaires ». Il reste la porte institutionnelle, le périmètre restreint, le flot d’informations, les interfaces de recherche pour ceux qui savent ce qu’ils peuvent trouver derrière, les longues listes de résultats à scanner, à filtrer, tout autant de barrières invisibles qui, malgré les meilleures volontés du monde, limitent l’accès aux œuvres. Il s’agissait de penser une interface qui décloisonne les domaines par des liens directs entre les œuvres, efface délibérément l’institutionnel, en ne gardant que les contenus dans un contexte d’usage centré sur des pratiques communes, voir des affiches et lire des livres. S’effacer pour faire voir, se liquéfier par les données pour mieux circuler et irriguer.
Enjoy!
