- Corot. Le peintre et ses modèles
- De Corot à l’art moderne. Souvenirs et variations
- Corot 1796-1875
- Le musée Saint-Raymond à la pointe
- D’autres expositions encore
- Mirabilis
- Explorer les expositions sur Crotos
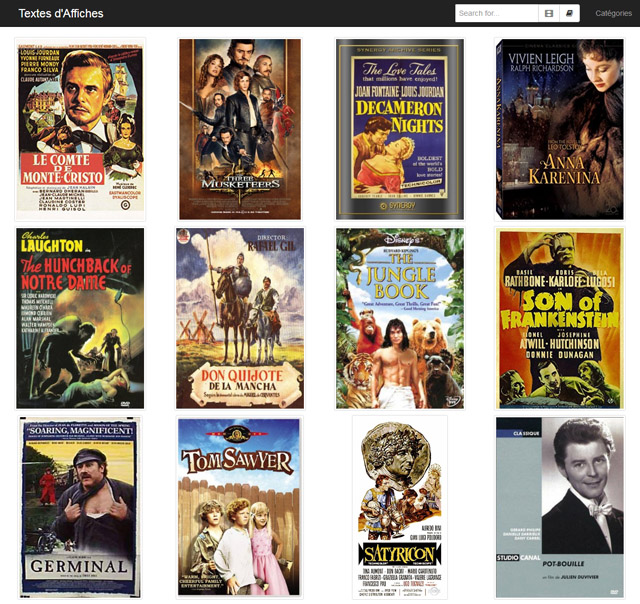
Corot. Le peintre et ses modèles
En 2018, s’est tenue au musée Marmottan, à Paris, l’exposition Corot. Le peintre et ses modèles. Une occasion rare et précieuse d’apprécier, dans un ensemble réuni sous le commissariat de Sébastien Allard, les œuvres de l’artiste.

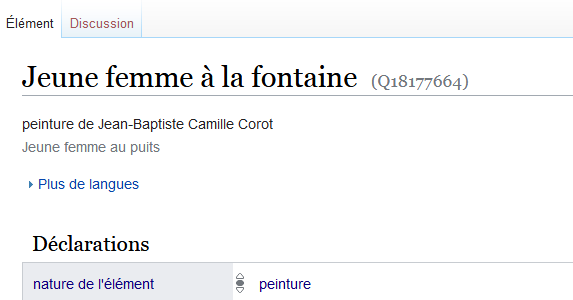
Jeune femme à la fontaine, Jean-Baptiste Camille Corot, vers 1860
en dépôt au Musées d’art et d’histoire de Genève, Fondation Jean-Louis Prevost-Fondation Gandur pour l’Art
Corot. Le peintre et ses modèles cat.43, Wikidata : Q18177664.
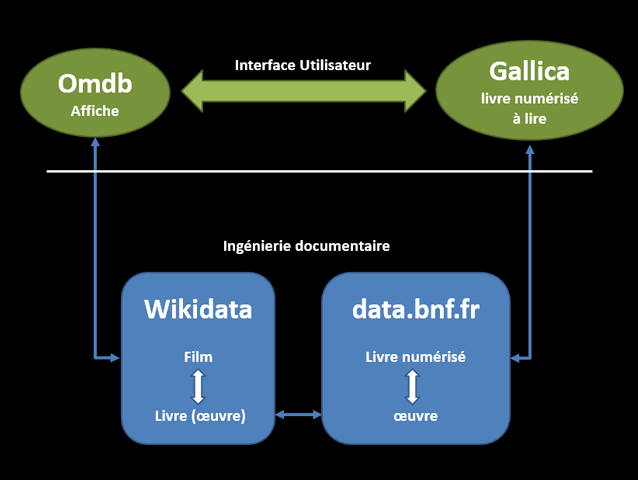
Une exposition, c’est une expérience sensible et c’est aussi l’histoire de l’art en train de se faire. Une heureuse alchimie de plaisir et de savoir. À ce titre, les catalogues sont précieux pour retrouver, garder souvenir, comme pour bénéficier d’un travail d’érudition et d’analyse sur l’ensemble comme sur le détail. Ainsi connaître les œuvres d’une exposition est utile. Avoir la liste des œuvres d’une exposition permet d’avoir trace de celles présentées, dont simplement on a le souvenir ou circulant rarement, de retrouver la production scientifique ou encore de situer le contexte de présentation. Dans ce domaine, la base Salons 1673-1914, réalisée par le musée d’Orsay et l’INHA, est exemplaire.
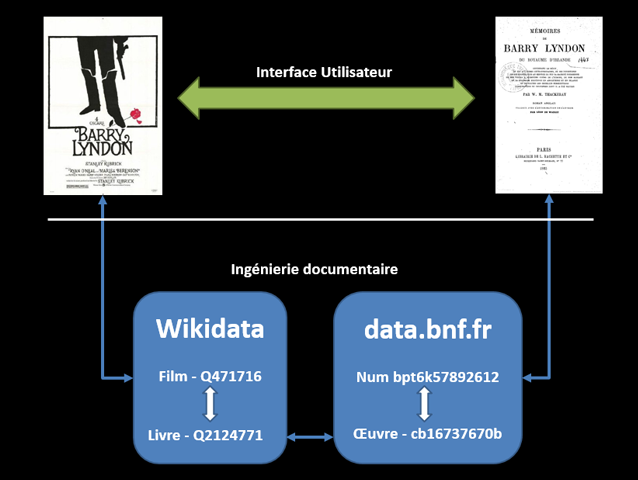
Parmi les autres projets faisant l’inventaire des œuvres réunies pour une exposition, il y a aussi Wikidata. Bien sûr il ne s’agit pas de substituer au catalogue qui constitue un ensemble éditorial spécifique, plus large qu’une liste d’œuvres, mais bien de s’appuyer sur les capacités documentaires de Wikidata pour dresser cette liste, lier les œuvres avec d’autres, tant au sein de Wikidata que vers des ressources externes. Comme cela a déjà été évoqué à propos de l’indexation iconographique, Wikidata constitue une gigantesque base de données d’œuvres d’art. Les peintures y sont très largement représentées mais pas seulement ; on y trouve sculptures, dessins, estampes, céramiques, artefacts notables… Plus globalement, parce que c’est un projet encyclopédique, toute œuvre de l’esprit et des mains humaines suffisamment notoire y a sa place.
Pour la documentation d’une exposition sur Wikidata, il est possible de :
- créer l’élément de l’exposition. Exemple : Q50380122 – Corot. Le peintre et ses modèles
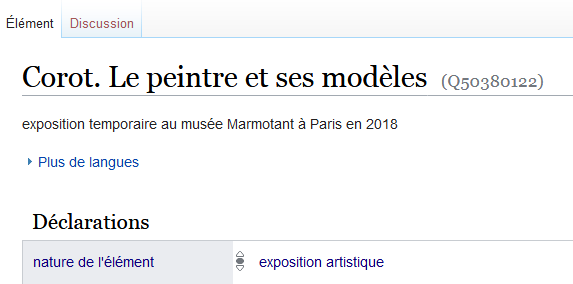
- créer l’élément du catalogue. Exemple : Q50380126 – Corot. Le peintre et ses modèles

- créer si besoin les éléments des œuvres. Ici, s’appliquent les critères de notoriété de Wikidata. Exemple : Q18177664 – Jeune femme à la fontaine
- renseigner l’exposition dans l’historique des expositions (propriété P608) de l’élément œuvre. Exemple :

- renseigner le numéro de catalogue dans les éléments œuvres (propriété P528) avec en qualificatif le catalogue (propriété P972). Exemple :

Ceci fait, on dispose de données accessibles, requêtables et réutilisables. Parmi les intérêts de Wikidata, se trouve notamment la possibilité de relier les éléments à la base de collections du musée ou autres ressources descriptives. Ainsi l’élément Jeune femme à la fontaine pointe via la propriété décrit à l’URL/P973 vers la notice sur le site des musées d’Art et d’Histoire de Genève où est conservé le tableau.
En utilisant le langage de requête SparQL (cf. Wikidata Enpoint SparQL et les peintures de Goya), on peut dresser automatiquement la liste des œuvres :
Exposition Corot. Le peintre et ses modèles sur l’Enpoint SparQL de Wikidata :
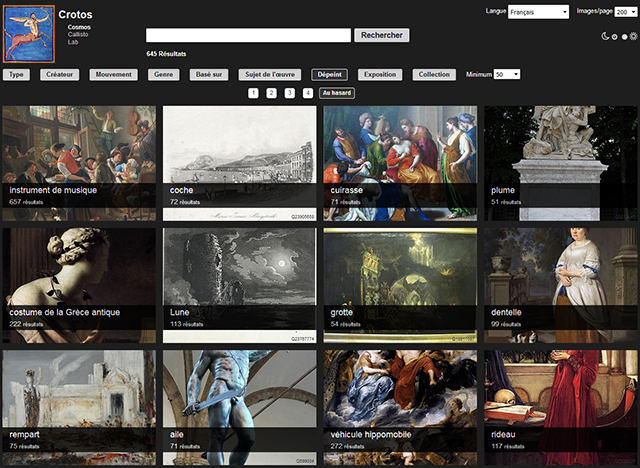
Si l’on souhaite voir des reproductions au cas elles soient disponibles sur Wikimedia Commons et renseignées sur Wikidata, on peut aussi utiliser le projet Crotos (décrit par là) :
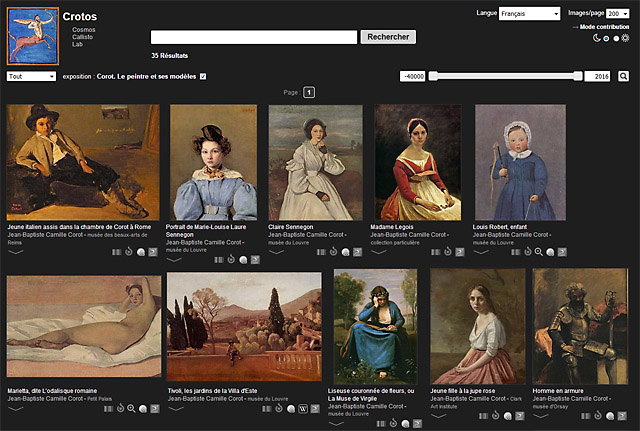
Corot. Le peintre et ses modèles sur Crotos
Il manque encore souvent des images. Et souhaitons-nous de passer pleinement à l’époque qui s’amorce, où les reproductions d’œuvres d’art du domaine public sont facilement accessibles et librement diffusables.
De Corot à l’art moderne. Souvenirs et variations
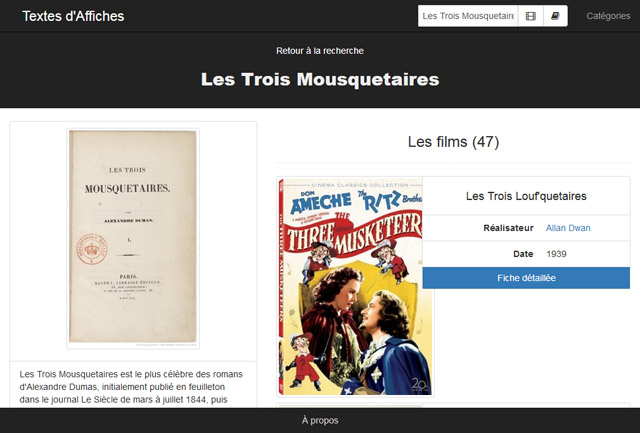
S’il est possible de documenter une exposition récente, il est tout aussi possible de faire de même pour une exposition plus lointainement passée.
Et justement, De Corot à l’art moderne. Souvenirs et variations. Cette exposition sous le commissariat de David Liot, Michael Pantazzi et Vincent Pomarède, eut lieu au musée des Beaux-arts de Reims en 2009. De la même façon que précédemment on peut créer les éléments de l’exposition, du catalogue et des œuvres, si nécessaire. En renseignant pareillement les historiques d’expositions et les numéros de catalogue, on peut établir la liste des œuvres de cette exposition.
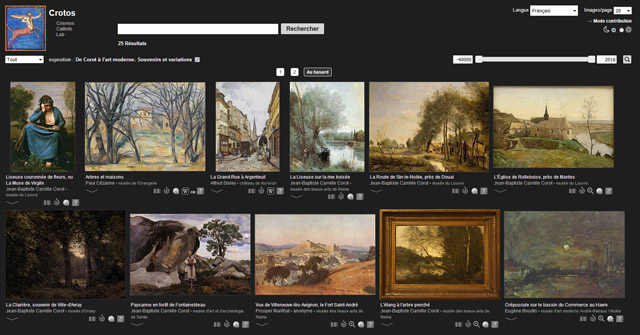
De Corot à l’art moderne. Souvenirs et variations sur Crotos
Corot 1796-1875
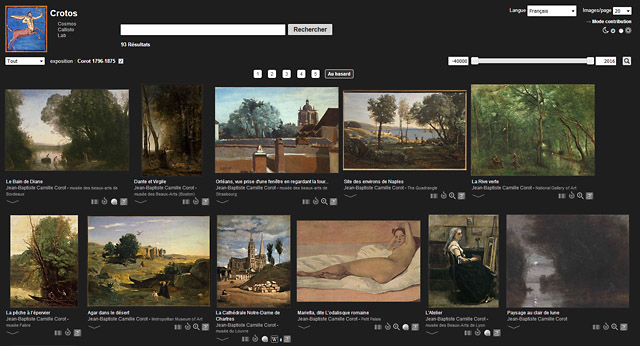
Continuons à remonter dans le temps. En 1996, s’est tenue une grande exposition Corot 1796-1875 aux galeries nationales du Grand Palais, sous le commissariat conjoint de Gary Tinterow, Michael Pantazzi et Vincent Pomarède. Un ensemble de 163 œuvres du Louvre et d’ailleurs, heureusement réunies.

Corot 1796-1815, couverture du catalogue de l’exposition, éd. Réunion des musées nationaux, Paris, 1996
Ici encore, on peut retrouver avec SparQL la liste des œuvres.
Ou encore les apprécier sur Crotos :
Pour ces 3 expositions Corot, sources en main, il a été possible de renseigner au passage, si indiqué, l’identifiant Robaut, dont L’Œuvre de Corot fait première référence pour les travaux de l’artiste. Ainsi Wikidata peut s’inscrire dans une continuité scientifique d’histoire de l’art tout en offrant de nouvelles perspectives.
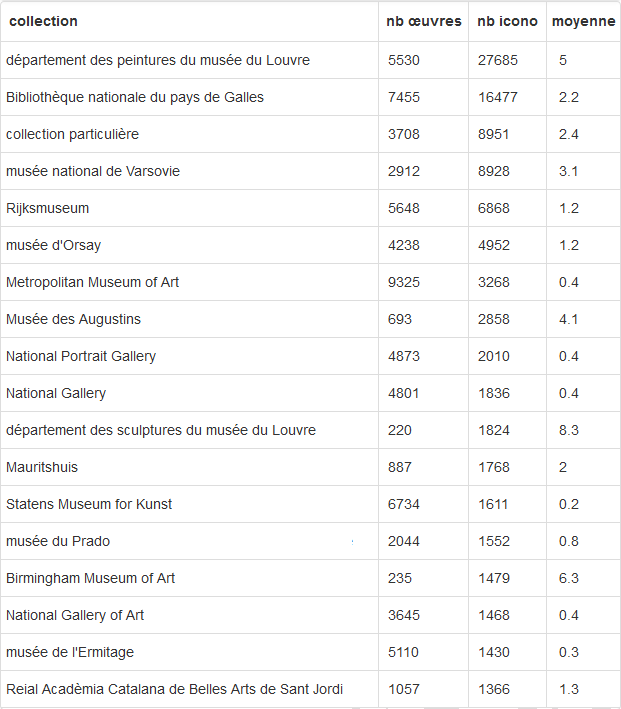
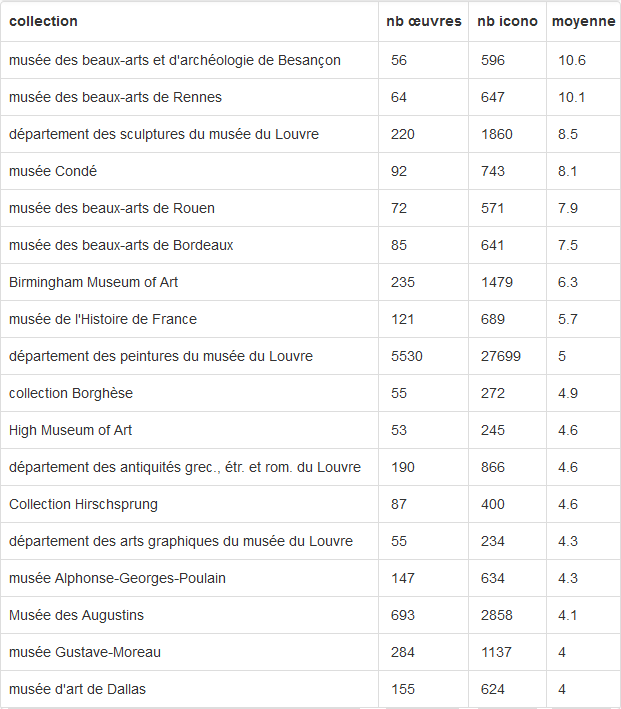
Les champs de recherche sont grands et encore largement à explorer. Par exemple, on peut aisément en une requête retrouver la liste des collections d’où sont issues les œuvres de Corot pour ces 3 expositions.
SELECT DISTINCT ?CollectionLabel ?PaysLabel
(COUNT(distinct ?item) as ?NombreOeuvres)
WHERE
{
# Corot 1796-1875
{?item wdt:P608 wd:Q41288846.}
# De Corot à l'art moderne. Souvenirs et variations
UNION
{?item wdt:P608 wd:Q56755276.}
# Corot. Le peintre et ses modèles
UNION
{?item wdt:P608 wd:Q50380122.}
# Créateur : Jean-Baptiste Camille Corot
?item wdt:P170 wd:Q148475.
?item wdt:P195 ?Collection.
OPTIONAL{?Collection wdt:P17 ?Pays.}
SERVICE wikibase:label {
bd:serviceParam
wikibase:language "[AUTO_LANGUAGE],fr".
}
}
GROUP BY ?CollectionLabel ?PaysLabel
ORDER BY DESC(?NombreOeuvres)
La requête donne le résultat suivant :
Le musée Saint-Raymond à la pointe
De novembre 2017 à mars 2018 s’est tenue au musée Saint-Raymond, musée des Antiques de Toulouse, l’exposition Rituels Grecs : une expérience sensible, avec en commissariat scientifique Adeline Grand-Clément, Evelyne Ugaglia, Claudine Jacquet, Amandine Declercq et Ghislaine Vandensteendam. Déjà sur Wikidata on peut retrouver la liste des œuvres de l’exposition.

Péliké, Peintre du Vatican V5, vers -400/-380 av. J.-C. musée Saint-Raymond, musée des Antiques de
Toulouse, inv. 26316, Wikidata : Q42309782, présenté à l’exposition Rituels Grecs : une expérience sensible
Photo : Caroline Léna Becker | cc-by-4.0
Mais l’effort du musée, porté par une lumineuse et productive impulsion, est bien plus large puisque d’autres expositions s’étant tenues au musée ont été traitées. Cette contribution faisait notamment partie de la création des éléments Wikidata pour les céramiques grecques du musée. Pour chaque élément, les expositions ayant présenté ces œuvres ont été renseignées, d’après les données disponibles dans la base du musée.
Grâce à cette importante contribution, il est possible, entre autres choses, de lister parmi ces expositions celles ayant au moins un élément sur une œuvre du musée :
D’autres expositions encore
Parmi les contributions sur les expositions, il y en a eu plusieurs autour des peintures des écoles du Nord, avec notamment :
Autres contributions notables :
- Velázquez, avec, pour cette exposition, une image pour chaque œuvre
- Vermeer et les maîtres de la peinture de genre, pareillement toutes les œuvres ont une image
- La Danse de la Vie – La collection de l’Antiquité à 1950, de la Galerie nationale d’Oslo
Il y a même une exposition virtuelle organisée dans le cadre d’Europeana, avec une sélection de 10 œuvres pour chaque pays de l’Union Européenne :
Ou encore les Salons, encore largement incomplets mais le cadre documentaire est présent :
Mirabilis
L’exposition Mirabilis (Wikidata : Q56542637) qui présente les collections des musées d’Avignon, sous le commissariat général de Pascale Picard, et qui se tient actuellement dans la Grande Chapelle du Palais des Papes à Avignon jusqu’en janvier 2019, fait l’objet d’une documentation sur Wikidata. La contribution est actuellement en cours. Celle-ci comprend également le versement des reproductions des œuvres sur Wikimedia Commons. Cette contribution permet non seulement de partager largement, d’offrir de la matière de qualité pour enrichir les projets Wikimedia ou autres mais aussi d’inscrire ces ressources dans un vaste ensemble documentaire tant pour la recherche, la connaissance (libre) que pour la délectation.
Explorer les expositions sur Crotos
Si l’on souhaite parcourir les expositions artistiques sur Wikidata, il est possible de naviguer dans une interface dédiée sur le site Crotos : Cosmos / Expositions.
L’occasion de découvrir et, pourquoi pas, celle aussi de donner envie de contribuer. Comme tout projet Wikimédia, la contribution est ouverte à toutes et à tous ; n’hésitez pas !
Cette documentation des expositions sur Wikidata démarre à peine, beaucoup reste à faire dans l’océan de ce qui a été produit. Mais rien n’empêche d’avancer. L’appareillage documentaire est là, solide (base orientée entités, propriétés adéquates, données normalisées, multilinguisme, large périmètre, évolutivité) . En matière de beaux-arts, de peinture surtout, les nombreuses œuvres déjà présentes sur Wikidata facilite l’indexation et il est toujours possible de créer de nouveaux éléments.
Et ce peu qui a été fait, est déjà directement accessible et l’est pour longtemps. Le plaisir d’apporter sa pierre, de diffuser les connaissances, de partager son émerveillement et de se souvenir de Corot.
Enjoy!

La Clairière, souvenir de Ville-d’Avray, Jean-Baptiste Camille Corot, 1869-1872
en dépôt au musée des beaux-arts de Nice, collection musée d’Orsay RF 1795
Corot 1796-1875 cat.149, De Corot à l’art moderne. Souvenirs et variations cat.32, Wikidata : Q17491901.